1.1 프로세서 구조 & 조직
모든 현대의 일반 목적 컴퓨터들은 "Stored Program Concept"를 따른다.

프로세서는 50년이라는 시간이 지남에 따라 성능은 ↑, 가격은 ↓.
컴퓨터의 운영 방법 자체는 변한 것이 없다.
-> 그 이유는 컴퓨터의 발전의 원인 대부분이 전자공학기술의 발전에 기인하기 때문이다.
-> 즉, 가장 큰 변화로는 진공관 (Vacuum Tubes) - 트랜지스터 - ICs - VLSI
- 진공관은 높은 진공 속에서 금속을 가열할 때 방출되는 전자를 전기장으로 제어하여, 정류, 증폭 등을 얻는다.
- 트랜지스터는 3개 이상의 단자를 가지고 있고 npn, pnp형으로 분류된다.
- IC (집적 회로)는 수천에서 수천만 개가 넘는 트랜지스터 등등을 집적시킨 것.
- VLSI는 더 발전한 형태.
-> 트랜지스터의 소형화는 부가적으로 저가격화, 고속화, 저전력화를 수반하였다.
물론, 이러한 발전이 전자공학시술의 발전만은 아니고, 전자공학에 대한 깊은 이해에서 출발한 통찰력들이
컴퓨터 구조와 컴퓨터 구성이란 용어로 설명할 수 있다.
| 컴퓨터 구조란??? 컴퓨터 구조(Computer Architecture)는 사용자가 바라본 컴퓨터를 설명한다. 명령어 세트, 사용자 레지스터, 메모리 관리용 테이블의 구조, 그리고 예외상황 처리모델들은 컴퓨터 구조의 일부분들이다. |
| 컴퓨터 구성이란??? 컴퓨터 구성(Computer Organization)은 사용자가 볼 수 없는 부분을 설명한다. 파이프라인, 캐시, 테이블 조회용 하드웨어, TLB(Translation Look-aside Buffer)등은 구성의 일부분들이다. |
| 프로세서란 무엇인가??? 범용 프로세서는 이론적으로 말하자면 메모리에 저장된 명령어들을 실행하는 유한 상태 오토마톤(Finite-State Automaton)이라 할 수 있다. 시스템의 상태는 프로세서에 위치한 레지스터의 값들과 메모리에 저장된 값들에 의해 결정된다. 각각의 명령어는 이들의 상태의 변화를 정의하며 또한 다음번에 실행될 명령어들을 결정한다. |
| Stored-Program 컴퓨터 Stored-Program 디지털 컴퓨터는 명령어와 데이터를 한 메모리에 저장하며, 명령어들도 필요한 경우에는 데이터처럼 처리한다. 이 방법은 프로세서가 다음에 처리할 명령어를 스스로 생성하는 것(self modifying code)을 가능하게 한다. |
새로운 변화 및 발견으로는 가상 메모리, 캐시 메모리, 파이프라인, 파이프라인, RISC 등등이 있음.
- 가상 메모리는 각 프로그램에 실제 메모리 주소가 아닌 가상의 메모리 주소를 주는 방식
- 캐시 메모리는 자주 사용하는 데이터를 임시 저장해서 효율을 높이는 방식
- 파이프라인은 한 데이터 처리 단계의 출력이 다음 단계의 입력으로 이어지는 형태로 연결된 구조
- CISC란 Complex Instruction Set Computer의 약어로, 하나의 명령어 실행으로 가능한 많은 프로세스들을 수행하는 것이기본인 규칙
- RISC란 Reduced Instruction Set Computer의 약어로, 다수의 간단한 명령어들을 조합하여 신속하게 실행할 수 있다면 효율적이라는 아이디어. 파이프라인 개념을 채택하고 있음.
1.2 하드웨어의 추상화
컴퓨터의 시작은 트랜지스터들이 4개가 모여서 만들어진 NAND가 가장 기본인데, 이 NAND와 같은 게이트들은
Gate Abstraction이라는 것으로 추상화를 시켰다.

Gate Abstraction이란?
NAND와 유사하게 나머지 로직 게이트를 트랜지스터로부터 설계해나가는 것.
특징으로는 회로가 간단해진다, 컴퓨터는 트랜지스터의 종류에 의해 성능이 달라지기는 하지만, 기능은 달라지지 않는점 등이 있다.
추상화의 여러 단계
1. 트랜지스터
2. 논리 게이트, 메모리 셀, 특정한 회로
3. 1-비트 덧셈기, 멀티플렉서, 디코더, 플립플롭
4. 워드 덧셈기, 멀티플렉서, 디코더, 레지스터, 버스
5. ALU, 배럴 시프터, 레지스터 뱅크, 메모리 블록
6. 프로세서, 캐시 및 메모리 관리 구조
7. 프로세서들, 주변기기, 캐시 메모리, 메모리 관리 유닛
8. 시스템 기능을 구현하는 칩
9. PCB (Printed Circuit Board)
10. 이동전화, PC, 엔진 제어기
1.3 MU0 - 간단한 프로세서
MU0란?
간단한 프로세서의 형태로 다음과 같은 간단한 컴포넌트 (Components)들을 포함하고 있다
PC, ALU, ACC, IR, Instruction decorder, Control Logic
| PC (Program Counter) | CPU가 현재 실행하고 있는 instruction의 주소를 가리킴. |
| IR | PC가 가리키는 instruction의 주소에서 읽어온 instruction을 담아두는 기억장소 |
| Address Register | 현재 사용되는 Data를 access하기 위한 data의 주소를 가리키는 값을 담아두는 기억장소. |
| Data Register | Address Register가 가리키는 주소의 실제 값 |
| ACC | 특수한 register로서, 연산에 사용되는 값들을 저장하며, 연산의 결과값을 잠시 저장하는 일이 많으며, 외부 사용자가 직접 access할 수 있는 register가 아니고, CPU 혼자 독식하는 register |
| Decoder | IR에 가져온 instruction을 해석하여 CU에 넘김 |
| CU (Central Unit) | Decoder에서 받아온 것을 각종 제어 신호로 변환하여 제어신호를 발생 시킴 |
| ALU | 산술 연산을 담당하는 unit. |
항상 같은 일을 수행하는데,
1) Fetch (instruction을 메모리로부터 가져오고)
2) Decode (가져온 instruction을 해석해서 어떤 일을 하는 녀석인지 알아보고 register 값들도 확인)
3) Execute (Decoding된 instruction을 실행.)
MU0의 특징
- 가장 기본적인 Processort 구조로 Manchester대학에서 교육용으로 만들었다.
- PC, ACC, ALU, IR, Instruction decode and control logic으로 구성.
- MU0의 instruction set은 16비트를 기본으로 한다. (4bit: Opcode, 12bit: Address)
MU0의 Instruction Set

MU0 논리 설계 또는 MU0 논리회로 설계
- 데이터부 (DataPath) : 데이터의 이동, 저장 처리하는데 사용하는 part (ACC, PC, ALU, IR)
1. PC에서 가르키는 주소가 Address bus를 통해 Memory로 가게 됨
2. 해당 메모리 주소에 있던 값이 Data bus를 통해 IR로 가게 된다.
3. IR에서 해당 값의 opcode를 분석하여, control signal을 발생시키며, Address값을 분석하여
다시 해당 메모리 주소의 값을 불러들인다.
4. 메모리에서 불러 들인 값은 다시 Data bus를 통해 ALU로 가게 되며 여기서 아까 IR의 opcode의
명령에 맞게 알맞은 계산이 수행된다.
5. 수행된 결과값은 ACC에 저장된다. PC 또한 ALU를 통해 값이 증가됨을 아래의 글미을 통해 알 수 있다.
데이터부 설계

메모리에서 데이터를 읽고 쓰기 위하여 접근(access)하는 데 한 클록 사이클이 소요된다고 가정하면,
LDA S, STO S, ADD S, SUB 명령어는 2번 메모리 접근해야 하는 것을 알 수 있다.
한번은 명령어를 읽어오기 위하여 그리고 다른 한번은 Operand(Opcode가 사용하는 데이터)를 읽어 오거나
저장하는 데 사용된다.
또한, 두 사이클 동안 ALU가 전부 사용되지 않으므로 ALU가 사용되지 않는 사이클에서 PC를 증가시키면 된다.)
데이터부 동작
1. 메모리에 있는 Operand를 읽어오고 지정된 연산을 수행한다. (execute)
둘중의 하나 작업을 하는데,
1) 메모리에서 읽어온 오퍼랜드(Operand)와 누산기(ACC)의 데이터를 이용하여 ALU에서 지정된 연산을 수행하고 결과 값을 다시 누산기(ACC)에 저장하는 일
2. 다음 번 명령어를 읽어온다. (fetch)
-> 명령어의 주소를 ALU에서 계산하고 그 값을 다시 PC에 저장한다.
초기화
프로세서는 제일 처음에 알고 있는 상태에서 시작되어야 하므로, 대부분의 프로세서들은 리셋(Reset) 입력을 사용한다.
MU0에서는 리셋입력이 들어오면 ALU 출력이 0이 되게 만들고, 그 값을 PC로 전송하게 만들었다.
레지스터 전송레벨(RTL) 설계

추가된 것은 MUX와 Memory이고, 추가된 Control Signal 들은
MEMrq (Memory Request) : Memory에 접근이 되어질 때 1 (LDA STO ADD SUB) 그렇지 않을 때 0
RnW (Read, if negative, Write) : 1이면 Read, 0이면 Write
Asel, Bsel : MUX에서의 Selector 역할
PCce, ACCce, IRce : 각 레지스터 Enable Signal
ALUfs(ALU function signal) : ALU의 덧셈, 뺄셈 등을 결정하는 신호
제어회로
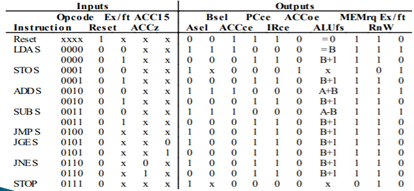
PC 레지스터와 IR레지스터의 클록인가 (Clock Enable) 신호 (PCce와 IRce)는 늘 함께 사용된다.
그 이유는 한 명령어를 읽어서 IR에 저장하는 데 걸리는 시간 동안에 다음 명령어의 주소를 ALU에서 계산해서 PC에 저장하는 것이 일반적이기 때문이다.
또한, ACC가 데이터 버스에 데이터를 인가(ACCoe = 1)할 때에는 메모리가 쓰기 동작(RnW=0)을 함께 수행해야 한다.
ALU 설계
ALU에서는 다음의 다섯 가지 함수를 실행할 수 있다.
A+B : 덧셈을 실행하고 합을 출력
A-B : A + not(B) + 1을 수행
B : B는 A를 0으로 하고 캐리입력도 0으로 조정하여 실행한다.
B+1 : A를 0으로 하고 캐리입력을 1로 조정하여 구현한다.
0 : 리셋 인가시

이 ALU에다가, 멀티플렉서, 레지스터, 제어회로, 버퍼회로들을 추가시키면 프로세서가 구성된다.
1.4 명령어 설계
- 향상된 프로세서의 성능을 보이기 위해서는 명령어 세트 설계는 매우 중요한 부분이다.
다음은, 명령어 설계의 종류이다.
4 - address inst
add d, s1, s2, next_i; d:=s1+s2를 나타내지만
다음 PC 값을 함께 포함하는 장점과 명령어가 길어지는 단점이 있음.
3 - address inst
add d, s1, s2; d:=s1+s2를 나타내며, PC값을 따로 계산 함.
2 - address inst
add d, s1; d:= d+s1으로 목적 주소에 s1값을 더하는 형태
1 - address inst
add s1; ACC:=ACC+d으로 ACC값을 목적주소로 s1값을 더하는 형태
0 - address inst
ADD; top_of_stack := top_of_stack + next_on_stack으로 스택 구조를 이용. tos값을 기준으로 더하고 뺀다.
- MU0는 1 address inst를 따르며, 표준 ARM같은 경우는 3 address inst를 따른다.
1.5 CISC vs RISC
CISC?
Complex Instruction Set Computer의 약자로,
High Level Language와 Machine Instruction사이의 Gap을 줄이는것을 목적으로 명령어를 가능하면
복잡하게 만들었다. 따라서, 파월풀한 Arithmetic Inst를 만드려고 노력하였다.
RISC?
Reduced Instruction Set Computer의 약자로,
CPU 명령어의 개수를 줄여 하드웨어 구조를 좀 더 간단하게 만드는 방식이다.
프로세서의 역할

- '정적인 측정'보다는 프로그램이 실제로 컴퓨터에서 실행되었을 때 얻을 수 있는 '동적인 측정'이 중요
- 따라서, 최적화시켜야 할 최우선 대상은 데이터 이동 명령어.
- 그래서 파이프라인 개념이 등장.
파이프라인
프로세서는 명령어를 단계적으로 실행한다. 일반적인 순서는
1. 메모리에서 명령어를 읽어온다. (fetch)
2. 읽어온 명령어를 해독한다. (decode)
3. 레지스터에서 필요한 오퍼랜드들을 읽어낸다. (reg)
4. 오퍼랜드들을 이용하여 연산 결과 또는 메모리 주소를 계산한다. (ALU)
5. 필요한 경우에는 메모리에서 데이터를 읽거나 쓴다. (mem)
6. 결과를 다시 레지스터에 저장한다. (res)
각 단계들은 프로세서의 서로 다른 부분들을 이용하기 때문에,
지금 명령어가 종료되기 전에 미리 다음 명령어를 실행시키는데, 이것을 파이프라인이라고 한다.
파이프라인 해저드

Read-After-write 파이프라인 해저드
컴퓨터 프로그램에서는 한 명령어의 결과를 다음 명령어에서 사용하는 것을 빈번하게 볼 수 있는데,
이러한 상황이 발생하면, 두번째 명령어는 첫번째 명령어의 결과가 나올 때까지 기다려야 한다.
지연 분기 (Delayed branch)
분기 명령의 바로 다음 명령을 분기 여부에 관계없이 실행하게 설계한 기술.
1.6 RISC (Reduced Instruction Set Computer)
RISC 구조
- 고정된(hard-wired) 명령어 해독 회로의 도입; CISC에서는 마이크로코드 방식을 이용.
- 파이프라인 도입; 예전의 CISC는 약간의 명령어의 실행의 중첩만을 허용하였음. 현재는 CISC에도 도입됨.
- 단일 사이클 실행; CISC는 한 명령어를 처리하기 위하여 많은 클록 사이클을 필요로 함.
RISC의 장점
- 작은 면적의 이용
- 단축된 개발 기간
- 고성능
RISC의 단점
- CISC보다 코드 밀도가 낮다.
-> Thumb arc를 활용하니 우월해짐.
- RISC는 x86 명령어들을 실행하지 못한다.
축소 명령어 집합 컴퓨터 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. RISC는 여기로 연결됩니다. 다른 뜻에 대해서는 RISC (동음이의) 문서를 참조하십시오. 축소 명령어 집합 컴퓨터(Reduced Instruction Set Computer, RISC, 리스크)는 CPU 명령어의 개수를 줄여 하드웨어 구조를 좀 더 간단하게 만드는 방식으로, 마이크로프로세서를 설계하는 방법 가운데 하나이며, SPARC, MIPS 등의 아키텍처에서 사용된다. ll 전통적인 CISC CPU에는 프로그래밍을
ko.wikipedia.org
- ARM system - on - chip구조 책